
本页面是youzimu.cc域名的跳转目的地。本页面属于FQ的博客,欢迎来逛逛~
YouzimuCC | 柚子木语音识别客户端
什么是YouzimuCC
YouzimuCC是柚子木字幕组成员FQ开发的一个语音识别软件,用于柚子木日常听译任务。顾名思义,这个软件帮助我们生成CC字幕。具体来说,这个软件是一个客户端,会调用各种云平台(比如:阿里云,IBM Cloud,Amazon AWS等)中的语音识别服务,将视频中的声音转换为英文文本,并允许生成srt文件,为听译提供方便。
开发本软件的原因有二:
其一,有一部分YouTube视频是没有CC字幕的,即使是auto-generated也没有。在这种情况下只能纯靠人工听写,这是很耗精力的。
其二,现在人工智能技术已经相当发达,语音识别已经变得可行。现在数家知名云服务提供商均已提供语音识别服务,但他们往往仅提供API(Application Programming Interface),这是计算机程序传递信息的方式,我们普通用户并不能直接利用。这是因为云服务提供商所面向的用户是应用程序开发者(程序猿)而不是我们这些真正具有听写和翻译需求的听译者。
当然,柚子木成员来自各行各业,只有小部分是计算机从业者,所以本软件提供一个简单易用的图形界面,代替用户与晦涩难懂的云提供的API沟通,一定程度上减轻听译的负担。
关于FQ:2015年9月加入柚子木YE时轴组;现任YG+YF时轴组长,YG听译组长,B站“柚Game”账号运营。更多三次元信息请点击页面下方LinkedIn链接。
下载YouzimuCC
下载页面: https://github.com/DavyVan/YouzimuCC-electron/releases
寻找最新的Release(V2.1.0),并下载对应操作系统的安装包即可。如下图: 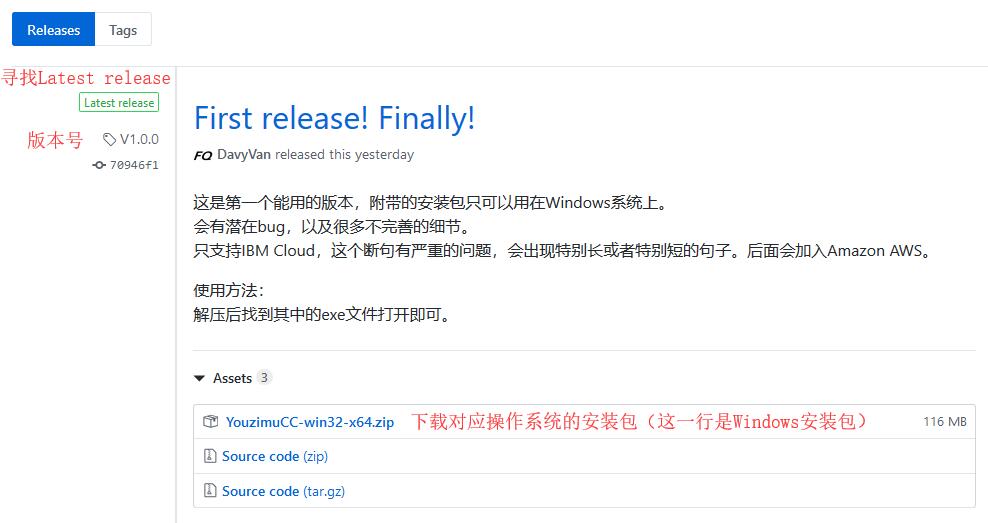
因为GitHub在国内访问经常不稳定,如果无法下载可以去群文件下载:听译综合群,搜索“YouzimuCC”文件夹
或者使用下面的百度网盘:https://pan.baidu.com/s/1lYSgZrZ8RDSePCzYaYXvhQ 提取码:ef78
身处海外的同学可以使用Google Drive更快地下载:https://drive.google.com/open?id=1-CzWY0fBX4SPG0i1RmfACOfuXvzdd69l
使用方法
视频教程:
0. 准备工作
使用本软件需要提前获取视频的MP3格式的音频文件,有很多YouTube视频下载网站都会提供MP3下载功能。
这里提供一个参考:https://www.clipconverter.cc/
1. 启动软件
a) 如果您下载的是zip格式的压缩包(仅适用Windows),解压之后直接找到其中的exe可执行文件并双击启动即可。如下图: 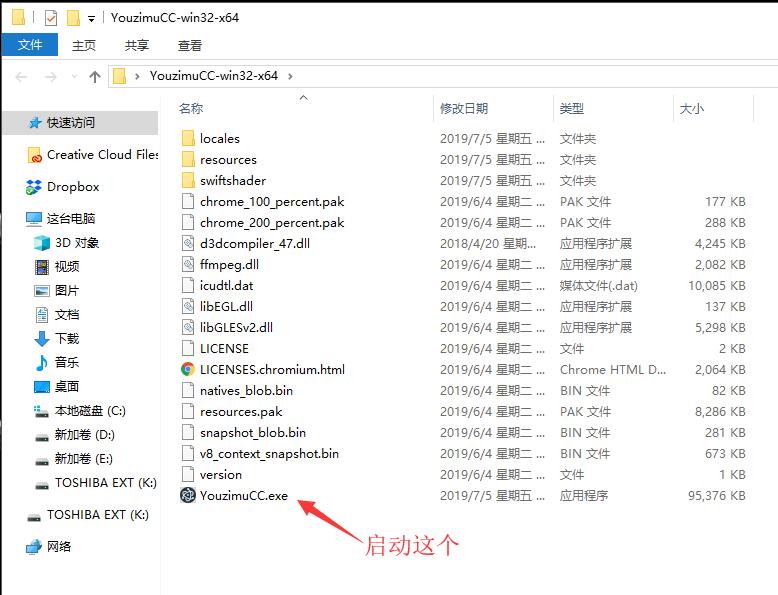
b) 如果您下载的是dmg格式的磁盘镜像文件(适用于macOS),打开之后将app文件拖拽到右侧Applications文件夹中,就像安装其他macOS应用一样,如下图: 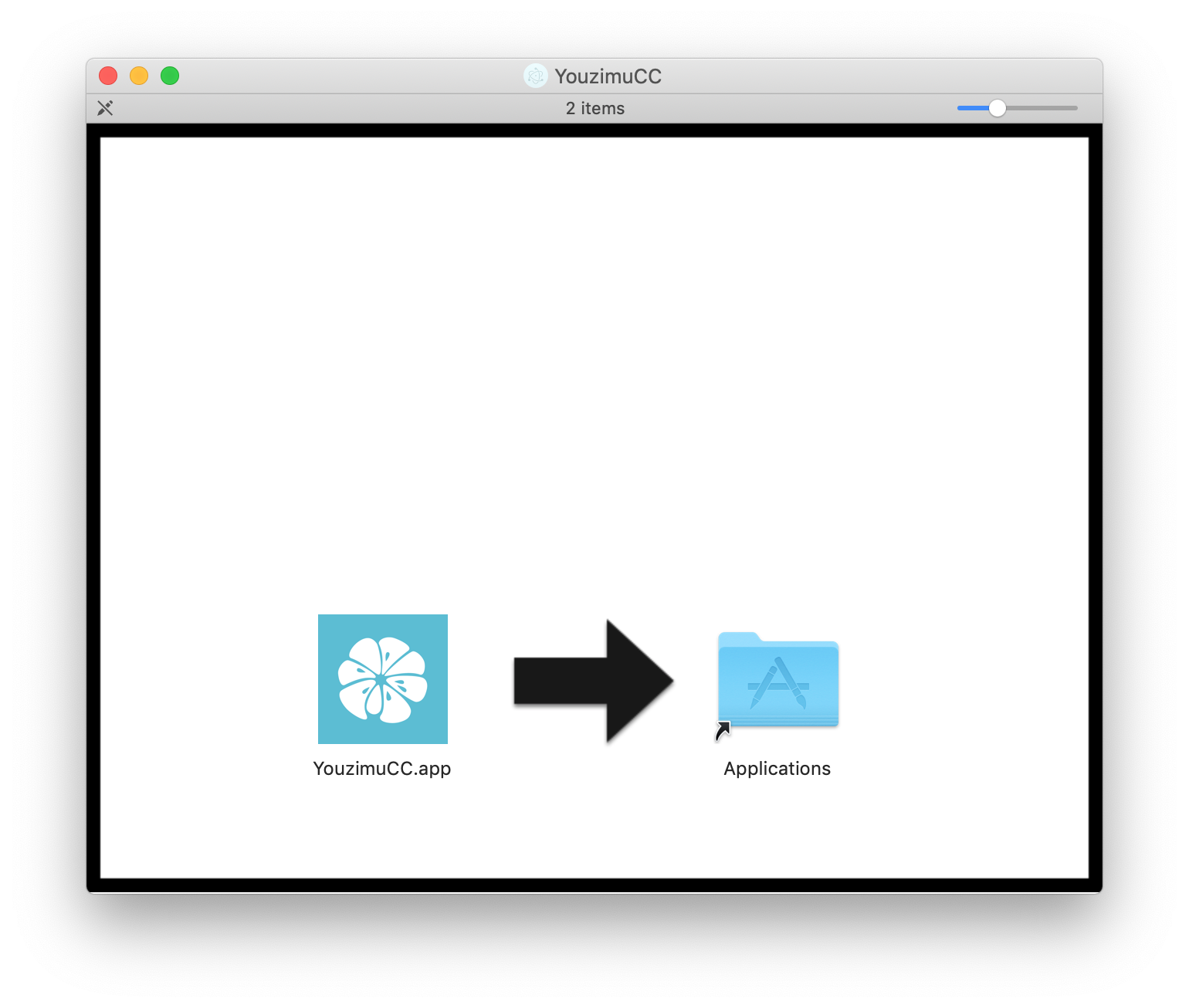
2. 确认设置
点击主界面右上角“设置”按钮可以打开设置界面(如下图),这里可以选择网络服务提供商、服务器地址、要识别的语言等。请在提交文件之前确认这些设置,尤其是经常进行多种语言识别的用户。因为每次处理时间较长,设置错误会带来额外的等待时间。 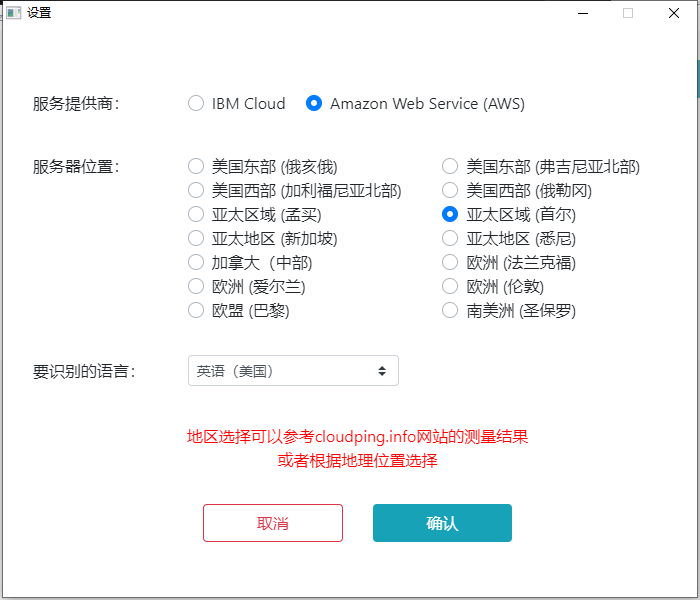
2. 选择文件
在软件主界面中,点击“选择文件…”按钮,并在弹出的文件选择框中选择预先准备好的MP3文件。
亦或者可以直接将文件拖拽至灰色区域并释放。这两种方式效果一致。如下图: 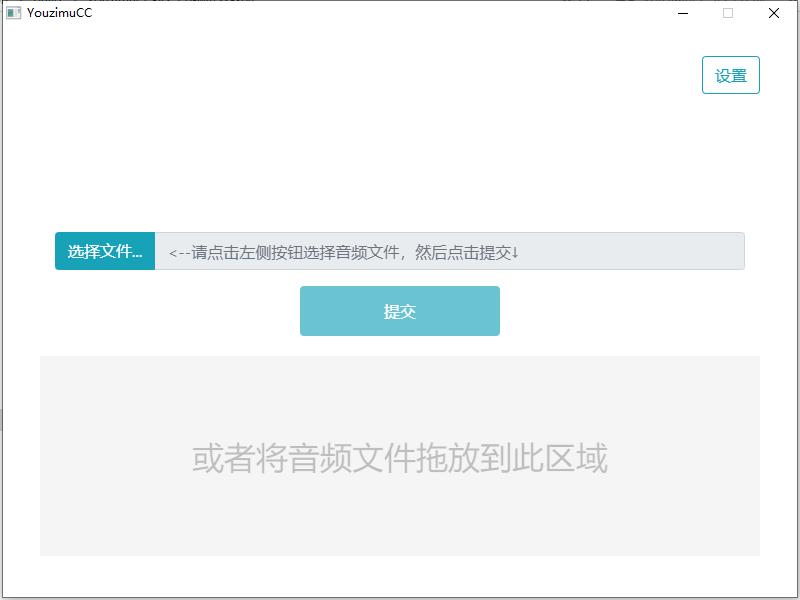
3. 提交
点击“提交”按钮,会弹出一个进度提示框,代表着语音识别程序已经开始运行。注意:在选择文件之后才允许点击提交按钮。 点击“提交”之后,主界面会变成灰色并禁止任何互动,直至关闭其他窗口(进度提示框、结果窗口),以此保证同时只能处理一个文件。
4. 等待结果
这个过程会比较漫长。时间主要花费在上传音频文件以及语音识别的过程:
因为本软件使用的IBM Cloud和Amazon AWS均位于中国境外,传输文件比较慢,所以比较长的视频其音频文件也比较大,需要更多时间上传;
语音识别基于人工智能技术,需要大量的运算,这涉及到复杂的实现原理,经验上来说,识别所需时间和视频时长是1:1的。
所以这一步请耐心等待,如果进度提示框显示“云端处理中……xx”或者“正在接收结果……xx”中的那个数字在缓慢增长,则证明确实在运行。如下图: 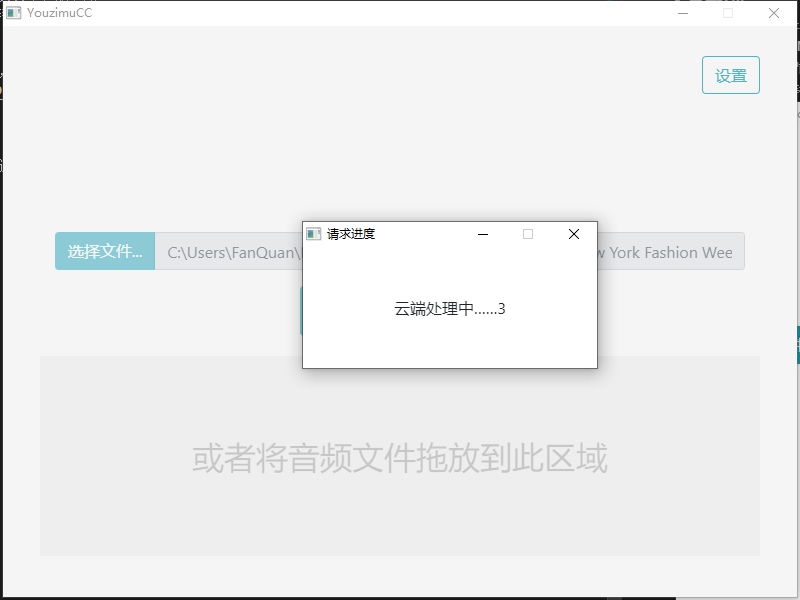
5. 获取结果
在完成语音识别之后,将会显示一个新的窗口,以列表的形式列出英文文本,如下图。
窗口最上方有一个“导出srt”按钮,顾名思义,可以将所看到的文本转换成srt,方便后面以此为基础进行听译。点击之后会弹出一个文件选择窗口,选择文件导出位置并填写文件名即可。通常导出过程只需要一瞬间。
注意:IBM Cloud识别出来的文本没有标点,现有技术无法准确断句,所以句子长度可能会比较蛋疼,使用AWS可以获得更好的结果(默认设置)。 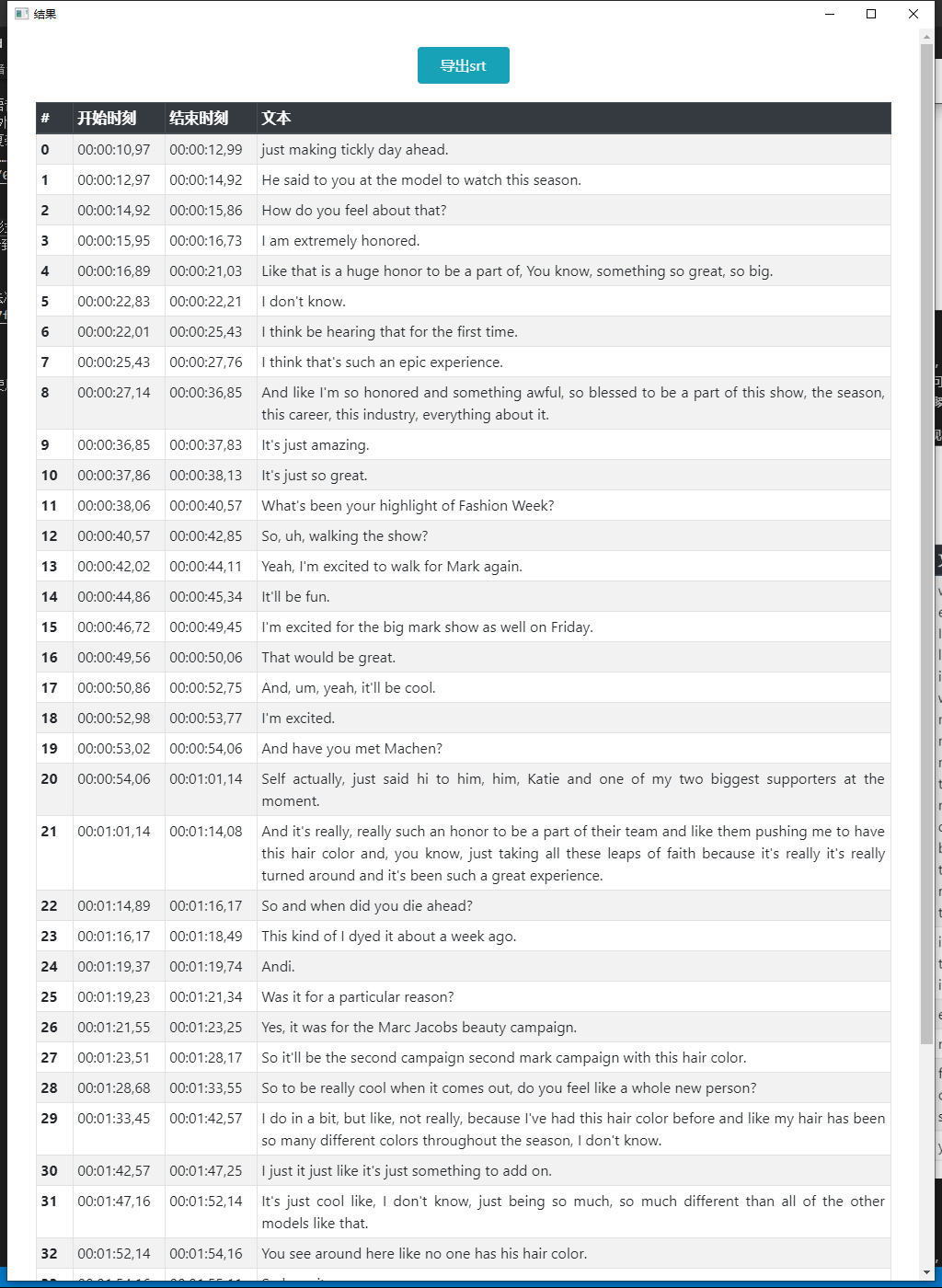
问题反馈
如果您在使用过程中遇到任何问题,可以通过QQ小窗直接反馈给我(听译大群搜索FQ)
会编程?想改进?
非常欢迎,如有需要请直接联系FQ讨论技术细节。 代码托管在GitHub